The GEO Visibility Gap — Fortune 500 AI Accessibility Report
Published 2026-04-20 · PROGEOLAB Research
The GEO Visibility Gap is the difference between what a website shows to human browsers and what it shows to AI answer engines. When a Fortune 500 company's homepage returns HTTP 200 to Chrome but HTTP 403 to ChatGPT-User, that company sits in the gap — invisible to the AI models answering questions about it, even though its content is current, correct, and publicly accessible in every other sense.
This report presents the first body-validated measurement of the gap across the Fortune Global 500. Between April 16 and April 19, 2026, PROGEOLAB probed 500 of the world's largest companies with four different user agents — a research bot, Googlebot, a Chrome browser, and OpenAI's ChatGPT-User — running 134,000 individual HTTP requests. Raw response bodies were captured and analyzed for WAF signatures, soft-404 pages, and content validity. The methodology is summarized in Four-UA Comparison and detailed in the full PDF.
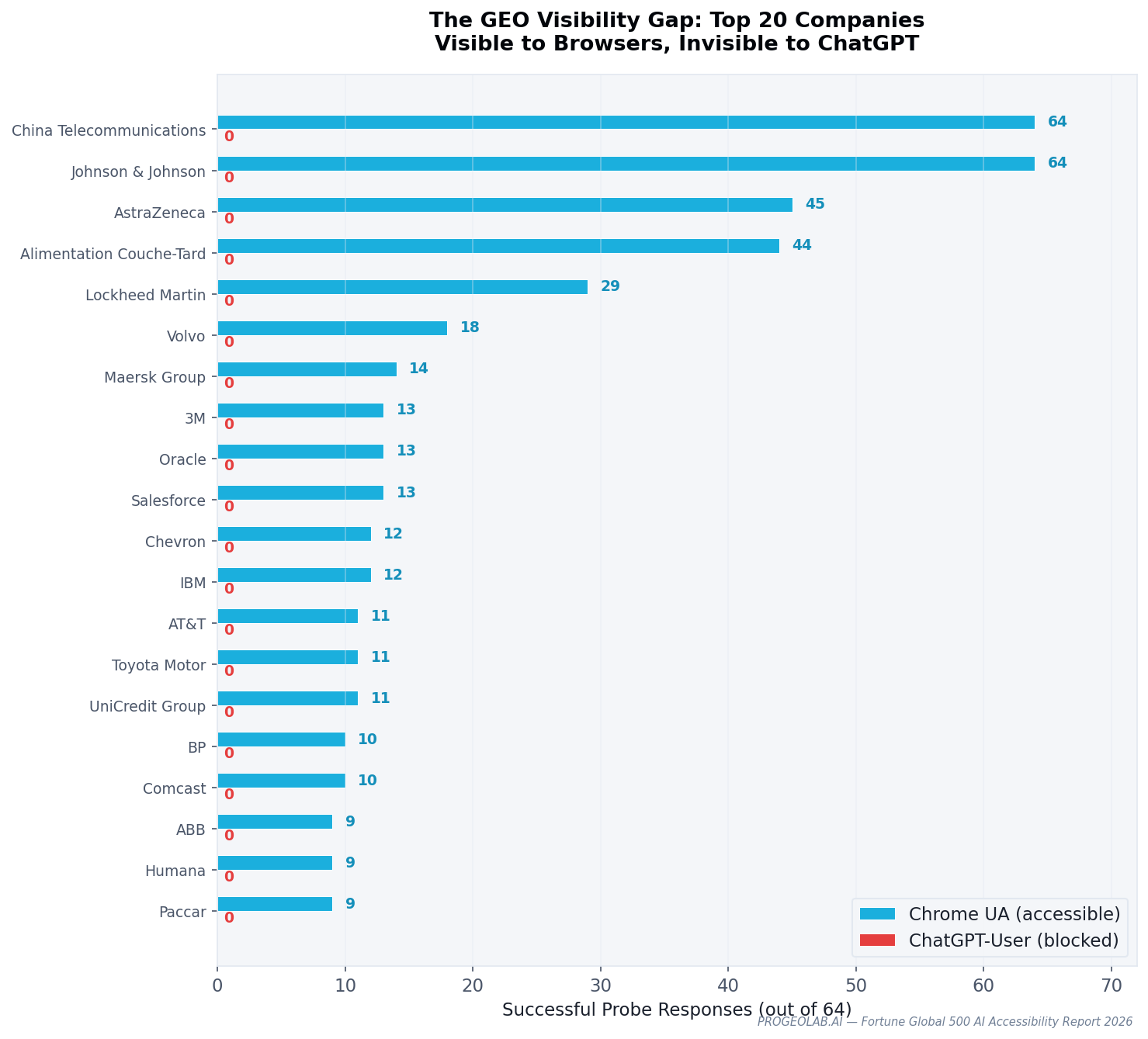
The headline finding: 53 Fortune 500 companies block ChatGPT-User while serving Chrome browsers — a 10.6% rate across the Fortune Global 500. The list spans Johnson & Johnson, Oracle, IBM, AT&T, Toyota, Goldman Sachs, and Salesforce, alongside 46 others.
AI-identified user agents perform worst
Across all 500 companies, Chrome reached 352 (70.4%). The research bot — an honest, unknown user-agent string — reached 325 (65.0%). Googlebot reached 307 (61.4%). ChatGPT-User reached only 300 (60.0%). The spread between Chrome and ChatGPT-User is 52 companies — the 53-company GEO gap, plus edge cases like Agricultural Bank of China (reachable to ChatGPT but not Chrome).
What makes the ChatGPT-User number diagnostic is the 403 count: ChatGPT-User receives 986 more HTTP 403 responses per run than Chrome. These are not accidents of general bot filtering — they are the quantifiable cost of identifying as an AI crawler.
Blocking operates at three distinct layers
The 53 companies in the gap don't all block AI the same way. Raw response body analysis reveals three technically distinct blocking layers, each requiring a different response from AI crawlers.
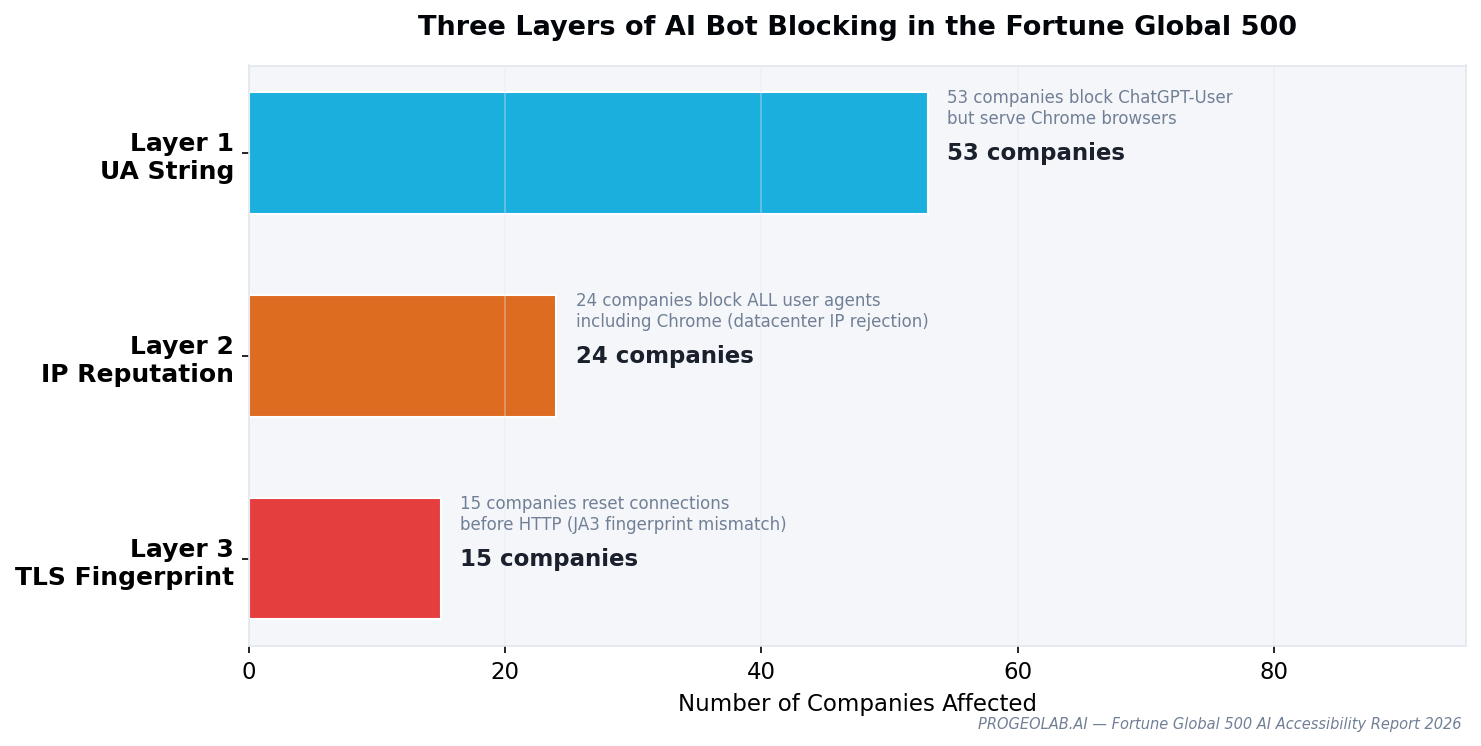
Layer 1 — User-Agent string (53 companies). The request header identifies as ChatGPT-User, and a WAF rule drops it. Trivially defeated by changing the UA string, but also trivially detected. Most WAF bot-management rules sit here.
Layer 2 — Datacenter IP reputation (24 companies). Any traffic from a known cloud or datacenter IP range is blocked, regardless of user agent. This defeats naive UA spoofing because the IP block precedes the UA inspection.
Layer 3 — TLS fingerprinting (15 companies). The TLS handshake itself reveals whether the client is a real browser or an HTTP library. By the time the HTTP request is parsed, the connection has already been rejected. This is the hardest to bypass: the fingerprint is set before a single HTTP header is sent.
A company using all three layers is functionally unreachable to AI crawlers regardless of how they identify themselves. A company using only Layer 1 is reachable to any retrieval system willing to spoof a UA string — which most aren't, because the AI platforms that matter (OpenAI, Anthropic, Perplexity) publish their agents openly and don't obfuscate.
Industry concentration
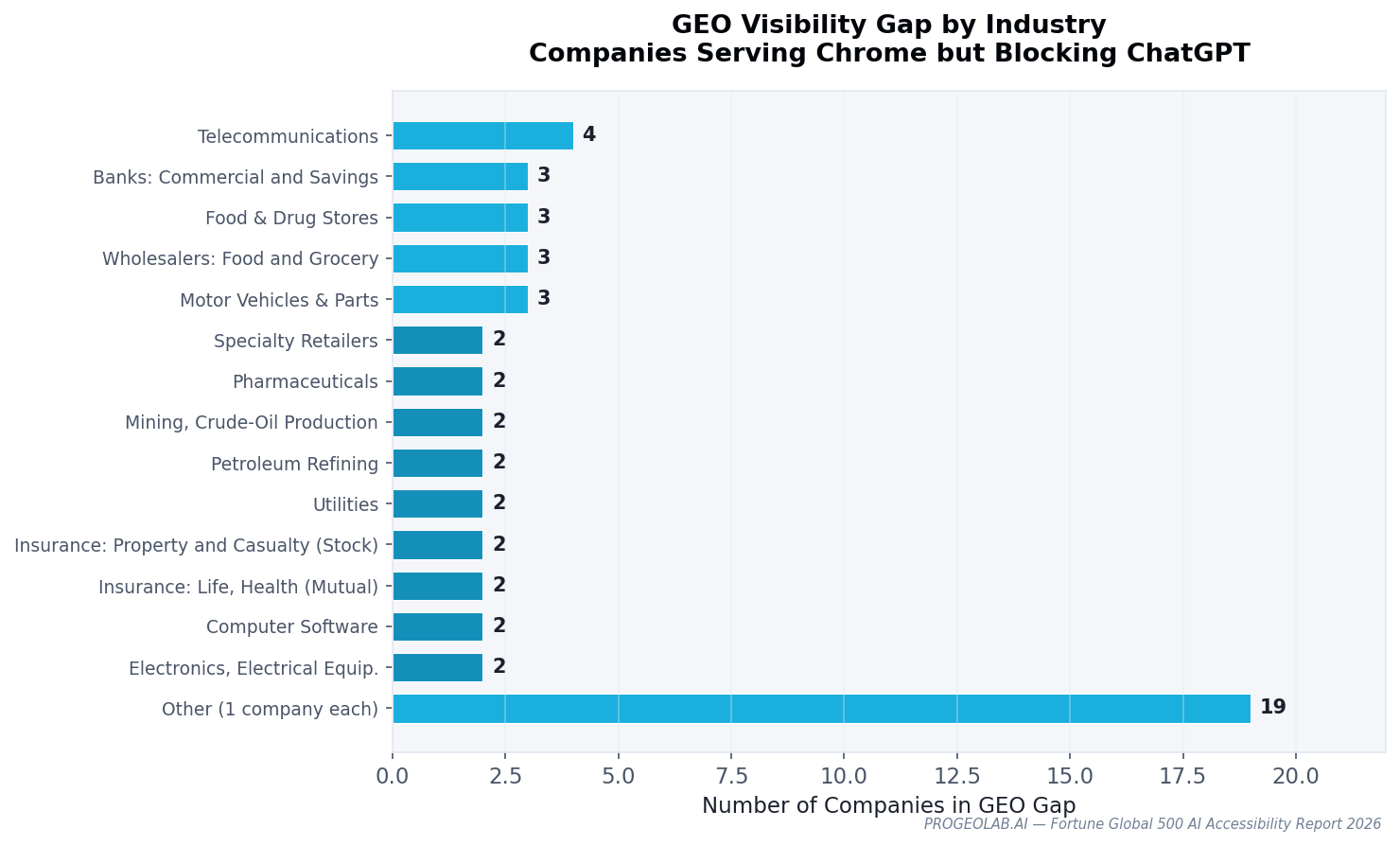
The GEO gap is not evenly distributed. Telecommunications leads with 26.7% of the sector in the gap. Software runs at 50% (small sample, but telling: the industry that builds AI also blocks it most — documented in Tech Giants Blocking AI). Banks sit at 5.3% — conservative but small. Metals, trading, and energy sectors show zero AI-specific blocking.
The llms.txt mirage
A parallel measurement, often repeated alongside accessibility, is llms.txt adoption. Status-code scanners report 353 Fortune 500 companies returning HTTP 200 on /llms.txt — a 70.6% adoption rate that has been widely cited.
Body validation tells a different story. Of those 353 responses, only 14 contain a real llms.txt file. The other 339 are soft-404 pages — HTML error templates, homepage redirects, and catch-all responses returned with a 200 status code. Real adoption: 2.8%. The 25× inflation factor is a cautionary note for any AI visibility metric that skips response body inspection.
One hundred sixty companies (41% of responding sites) serve catch-all pages that return 200 for any URL path. Most AI visibility audits, including PROGEOLAB's own early drafts, overstated llms.txt adoption until body validation was added.
Entity disambiguation is worse
Of 500 Fortune 500 homepages, 122 publish JSON-LD structured data. Only 55 use the sameAs property. And just three Fortune 500 companies link to their Wikidata entry: Apple (Q312), Comcast (Q1113804), and Repsol (Q174747).
Wikidata is how AI answer engines canonically resolve which "Apple" or "Comcast" you mean. When a query mentions a company name, the model checks whether the brand's own content asserts a canonical identity. Only three companies — of the world's 500 largest — currently make that assertion. The entity disambiguation gap is the quiet cousin of the accessibility gap: a brand can be perfectly reachable and still return ambiguous answers because nothing in its markup disambiguates it.
Why this matters
Two audiences should care about this report.
For enterprises, the most impactful action is auditing WAF bot-management rules for AI-specific user agents. The distinction between AI training crawlers (GPTBot, ClaudeBot) and user-initiated retrieval (ChatGPT-User, PerplexityBot) should inform policy — blocking one need not mean blocking both. Companies in the gap are not winning a privacy fight; they are ceding narrative to AI inference from secondary sources.
For AI companies, structural barriers persist beyond policy. IP reputation scoring and TLS fingerprinting block AI crawlers independently of robots.txt compliance. Implementing reverse DNS verification (as Google has done for Googlebot) and working with WAF vendors on native AI crawler verification would reduce the friction that drives blanket blocking.
What's in the full report
The gated PDF covers twelve chapters:
- Executive summary and methodology
- The four-user-agent reachability matrix
- The 53-company GEO gap, ranked and profiled
- The three blocking layers, with technical fingerprints
- The Googlebot impersonation backfire (32 companies penalize spoofing)
- The WAF landscape — F5 BIG-IP on 232 sites, plus Cloudflare, Akamai, Imperva
- The soft-404 problem (41% of responding sites)
- Industry-level analysis (15 sectors)
- Country-level analysis (13 countries)
- Enterprise recommendations
- AI-company recommendations
- Complete company-level appendix
The full PDF is 43 pages, includes 11 figures at 150 dpi, and is available below.