robots.txt and AI: How the Fortune 500 Polices AI Crawlers
Published 2026-04-20 · PROGEOLAB Research
An AI-specific robots.txt policy is the minimum deliberate step a website can take to govern how AI answer engines access its content. A line naming GPTBot or ClaudeBot — followed by Allow or Disallow — is a claim of intention. Silence defaults to whatever the WAF and the wildcard rules happen to do.
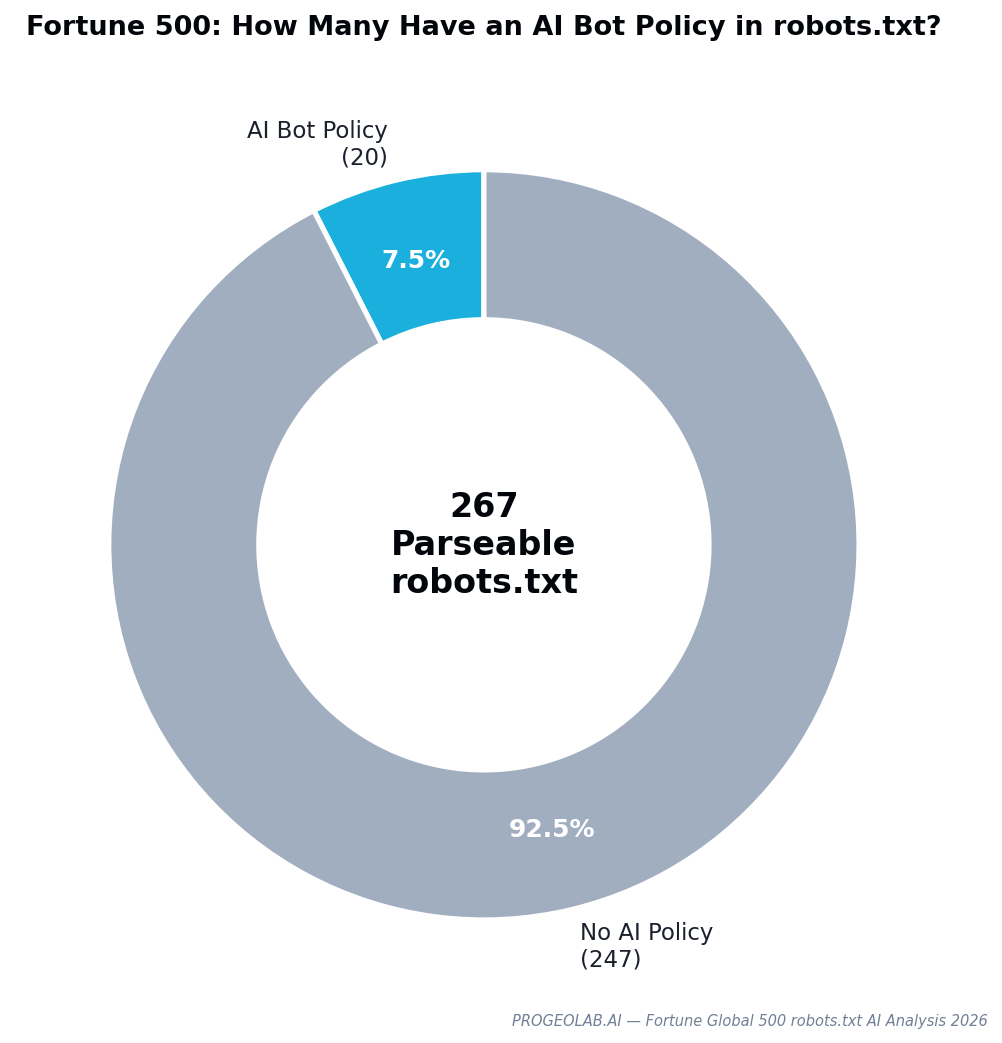
This report presents the first large-scale analysis of robots.txt AI bot policies across the Fortune Global 500. PROGEOLAB parsed the raw robots.txt bodies of 267 companies, extracted every User-agent directive, and cross-referenced declared policy against the actual four-way user-agent access data from the flagship audit. The finding, up front:
Of 267 parseable Fortune 500 robots.txt files, only 20 name any AI crawler. The other 247 — 92.5% — make no explicit decision at all. Their AI accessibility is governed by wildcard rules designed for search engines and by WAF configurations maintained independently of content policy.
The two extremes: Amazon vs HP
Inside the 20 companies with AI-specific policies, two stand out as opposite strategies. Amazon's robots.txt is the most comprehensive AI blocker in the Fortune 500 — naming and blocking 16 distinct AI crawlers, including training bots (GPTBot), retrieval bots (ChatGPT-User, PerplexityBot), and research bots (AI2Bot, CCBot). Amazon's bot-blocking strategy protects a purchase funnel from being summarized by third-party AI.
HP's robots.txt is the opposite. 10 AI crawlers are named and explicitly allowed, alongside regional sitemaps specifically for AI systems. HP is optimizing for cross-channel discovery — the bet that an AI answer mentioning HP products drives inquiries whose conversion economics are better than the alternative of being absent entirely.
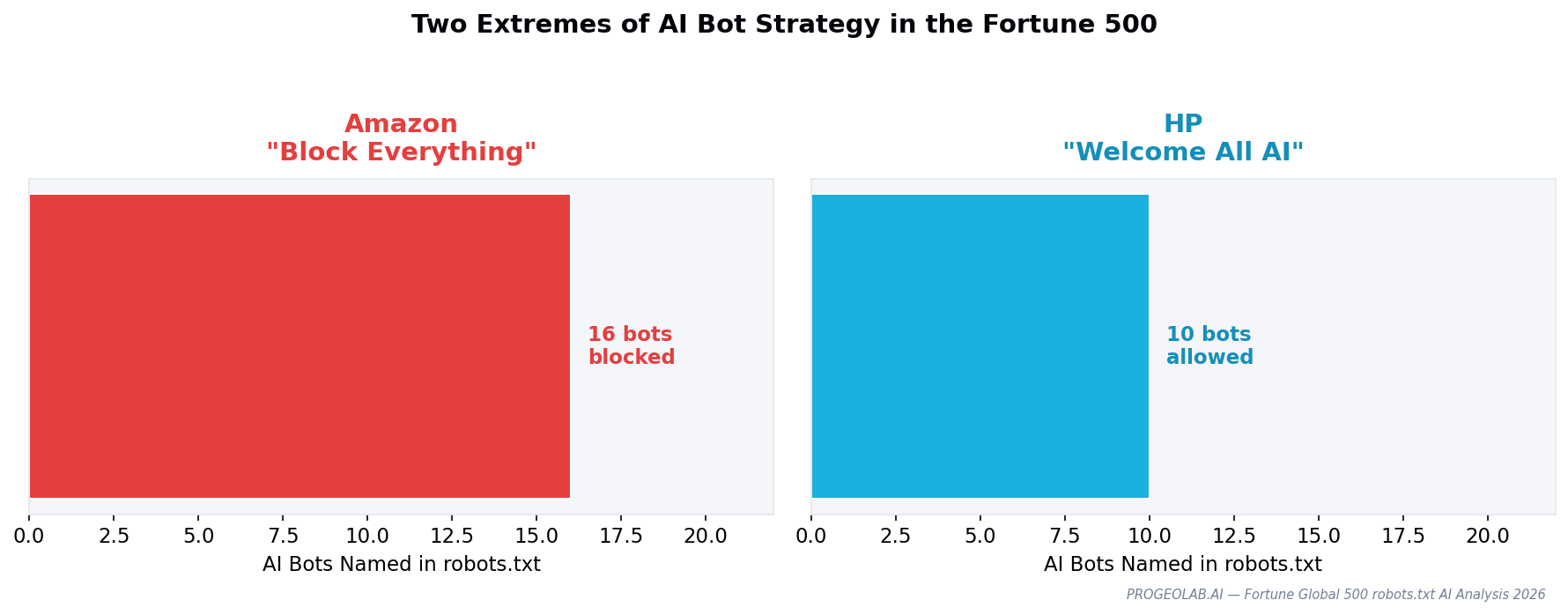
Neither position is wrong. What is wrong, analytically, is the 247 Fortune 500 companies that have taken neither.
GPTBot dominates bot recognition
Among the 24 distinct AI crawler names identified across the Fortune 500 corpus, three dominate. GPTBot is named by 15 of the 20 AI-aware robots.txt files. ClaudeBot appears in 12. Google-Extended — Google's AI training crawler, distinct from Googlebot — appears in 11. The long tail of AI crawlers (PerplexityBot, Bytespider, Amazonbot, CCBot, Applebot-Extended) appears in one-digit counts.
Only 8 companies in the Fortune 500 distinguish between training crawlers and retrieval crawlers. The distinction matters: GPTBot trains models; ChatGPT-User fetches a page in response to a live user query. Blocking one need not mean blocking both, and the business decisions behind each are different. Most Fortune 500 robots.txt files treat them identically — either all named bots Disallow, or all Allow.
robots.txt declarations do not predict actual access
Perhaps the most important finding in the report — and the one no prior robots.txt study has published — is that declared policy and actual access diverge.
Goldman Sachs' robots.txt explicitly allows GPTBot and ChatGPT-User. At the WAF layer, both are blocked. A researcher or journalist taking robots.txt at face value would report Goldman Sachs as AI-friendly. An AI crawler testing actual access would record 403.
The reverse case: Alibaba blocks GPTBot in robots.txt. But ChatGPT-User successfully fetches Alibaba homepage content. The WAF is not enforcing the robots.txt policy.
These inconsistencies are not edge cases. They result from content policy (owned by SEO/marketing teams) and security infrastructure (owned by WAF operators) being maintained by separate teams with separate review cycles. Any AI-readiness assessment based on robots.txt alone is unreliable; actual behavior requires active probing.
Four strategic templates
The 20 AI-aware Fortune 500 robots.txt files cluster into four template patterns:
- Block All AI (Amazon pattern). Explicit Disallow for every named AI crawler. Goal: protect the purchase funnel. Requires consistent WAF enforcement to prevent spoofed requests.
- Allow All AI (HP pattern). Explicit Allow for every named AI crawler. Goal: maximize cross-channel discoverability. Often paired with a dedicated llms.txt and sitemap for AI systems.
- Allow Search, Block Training (nuanced). Allow ChatGPT-User, PerplexityBot, Google-Extended; Disallow GPTBot, ClaudeBot (the training variants). Goal: appear in AI answers without contributing to model training. Technically fragile because training/retrieval distinction depends on the vendor honoring it.
- Selective Per-Model (partnership-driven). Allow specific named partners; Disallow everything else. Rare outside bilateral licensing deals.
The Templates guide publishes copy-paste robots.txt snippets for each of these four patterns, validated against the Fortune 500 data.
What's in the full report
The gated PDF covers:
- Complete directory of 24 AI crawler names with operator, purpose, and documentation links
- Full parse of all 267 Fortune 500 robots.txt files (518 user-agent sections)
- Amazon and HP case studies with line-by-line analysis
- Cross-reference table: robots.txt declaration vs actual four-UA access, per company
- Four template patterns with ready-to-paste text
- Appendix: every AI-aware Fortune 500 robots.txt file, unedited